Machine learning powers everything from voice assistants to fraud detection, but how do these systems actually learn? At the core of AI development are two major techniques: supervised and unsupervised learning. One follows a structured approach, learning from labeled examples, while the other dives into raw data to uncover hidden patterns.
Choosing between them isn't just about technical preference—it impacts accuracy, efficiency, and even business outcomes. Whether training AI to detect diseases or personalize recommendations, understanding these methods is crucial. This article breaks down their strengths and weaknesses and when to use each to get the best results from machine learning.
What is Supervised Learning?
Supervised learning is an approach where AI models are trained on labeled datasets. For each input, there is a corresponding correct output, which trains the model to learn relationships and patterns. The system gets better with time by comparing its prediction to actual outcomes and adjusting accordingly.
Supervised learning is a prevalent method employed in applications that demand classification or regression. Within classification tasks, data is split into classes—e.g., separating spam and non-spam emails. For regression tasks, supervised learning predicts numbers, e.g., stock values or weather temperatures. Supervised learning models rely on algorithms such as decision trees, support vector machines, and neural networks.
Supervised learning
is particularly good for situations where precision and reliability are required but at the cost of large amounts of labeled data, which is time-consuming and expensive to collect.
Pros of Supervised Learning
One of the greatest strengths of supervised learning is its accuracy. Because models are trained using pre-specified answers, they provide extremely precise results. Thus, they are good for applications such as fraud detection, speech recognition, and disease diagnosis, where mistakes can be disastrous.
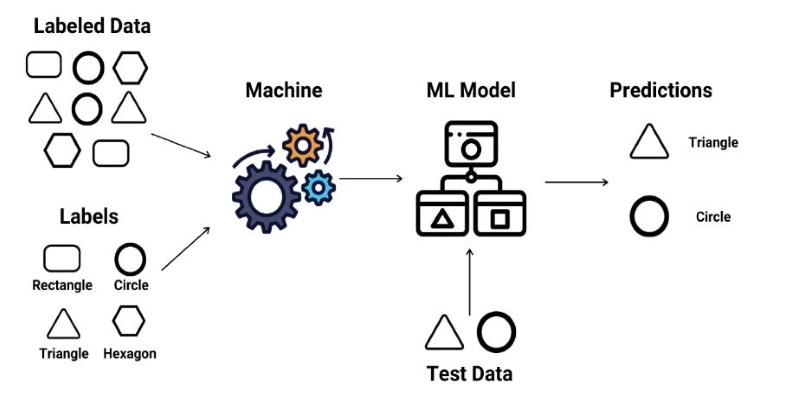
Another benefit is interpretability. Since the model is trained with structured data, its decision process is more transparent. This visibility is important in applications such as finance and medicine. Also, supervised learning models can be periodically updated with additional data, allowing for increased precision and adjustment for evolving trends with time.
Cons of Supervised Learning
Despite its accuracy, supervised learning has drawbacks. The biggest challenge is the need for large, labeled datasets, which can be expensive and time-consuming to collect, especially in fields like medicine and legal analysis.
Another issue is overfitting, where a model memorizes training data too well but struggles with new, unseen data. This reduces real-world applicability. Techniques like cross-validation help but require fine-tuning.
Additionally, supervised learning lacks the flexibility to discover unknown patterns, as it relies solely on human-labeled data rather than independently exploring hidden structures in raw information.
What is Unsupervised Learning?
Unsupervised learning takes a different approach, working without labeled data. Instead of being told what to look for, the model identifies patterns and relationships on its own. This method is particularly useful for exploring complex datasets where predefined categories do not exist.
The primary applications of unsupervised learning include clustering and anomaly detection. Clustering groups similar data points together, such as segmenting customers based on their purchasing habits. Anomaly detection identifies unusual patterns in data, which can be useful for detecting fraudulent transactions or cybersecurity threats.
Common unsupervised learning algorithms include K-means clustering, hierarchical clustering, and principal component analysis (PCA). Unlike supervised learning, which requires structured input, unsupervised learning can work with raw, unorganized data, making it ideal for large-scale data analysis.
Pros of Unsupervised Learning
One of the biggest advantages of unsupervised learning is its ability to discover hidden patterns in data. Without requiring labeled data, it identifies trends that may not be immediately obvious, making it valuable in genetics, customer behavior analysis, and financial research.
Another benefit is scalability. Since unsupervised learning does not rely on manual labeling, it can handle massive datasets efficiently, making it cost-effective for large-scale AI applications like recommendation systems in e-commerce and streaming platforms. Additionally, it adapts to new data without retraining, which is beneficial for cybersecurity and risk assessment.
Cons of Unsupervised Learning
Despite its flexibility, unsupervised learning has limitations. One major issue is unpredictability—without labeled data, its outputs may be ambiguous or misleading, making it difficult to evaluate accuracy.
Misclassification is another risk. Since there are no predefined categories, the model might incorrectly group data, leading to unreliable insights. This can negatively impact marketing strategies or customer segmentation.
Additionally, fine-tuning unsupervised models is challenging. Without a clear benchmark for performance, evaluating results requires extensive trial and error, making the process time-consuming and complex.
Key Differences: Supervised vs. Unsupervised Learning
The core distinction between these two learning methods lies in data labeling. Supervised learning requires structured, labeled datasets, making it ideal for predictive tasks. In contrast, unsupervised learning identifies patterns in raw data without predefined labels.

Accuracy and interpretability also differ. Supervised learning provides precise and explainable results, making it preferable for applications requiring transparency. Unsupervised learning, however, excels at finding unknown patterns but often requires additional interpretation.
Another major difference is scalability. While supervised learning needs extensive labeled data, unsupervised learning can analyze massive datasets with minimal human intervention, making it more practical for big data applications.
When to Choose
The choice between supervised and unsupervised learning depends on the problem at hand. If accuracy and predictive power are the main priorities, supervised learning is the best option. It is particularly useful for fraud detection, medical diagnoses, and automated translations. However, it requires high-quality labeled data, which may not always be available.
Unsupervised learning is better suited for exploratory analysis, where hidden patterns need to be uncovered. It is widely used in market research, customer segmentation, and cybersecurity. While it does not offer the same level of precision as supervised learning, it provides valuable insights from raw data.
Conclusion
Both supervised and unsupervised learning play essential roles in AI development, each catering to different use cases. Supervised learning is best for applications requiring accuracy and structured decision-making, while unsupervised learning is ideal for discovering patterns in complex datasets. The right choice depends on the project's specific needs, the availability of labeled data, and the desired level of interpretability. By understanding these differences, businesses and researchers can make informed decisions on how to leverage machine learning models effectively.











